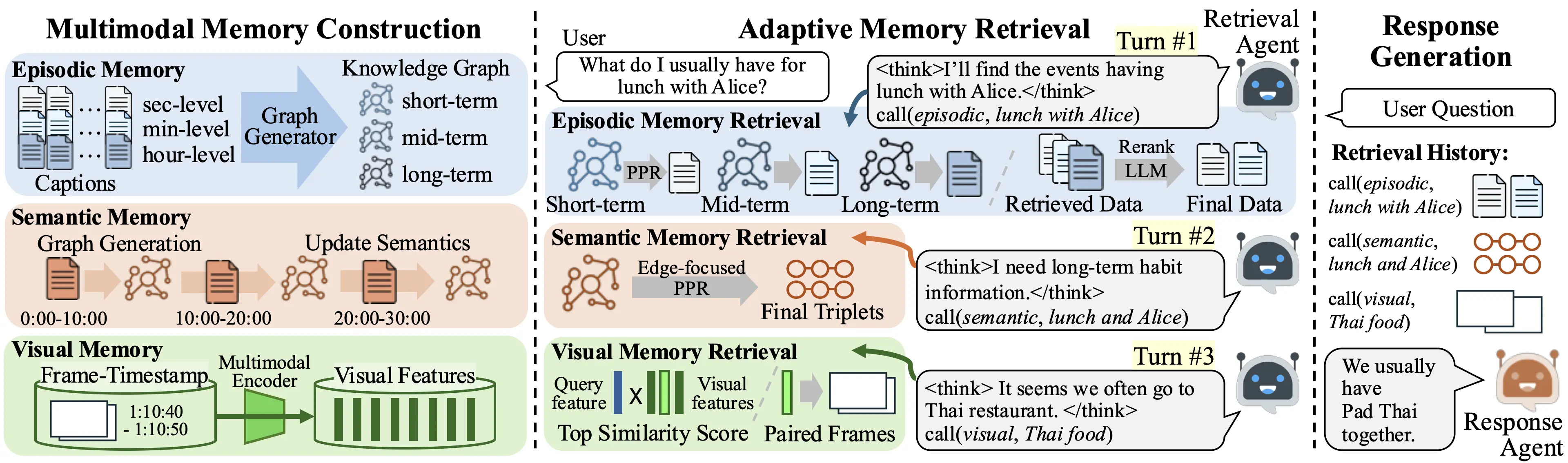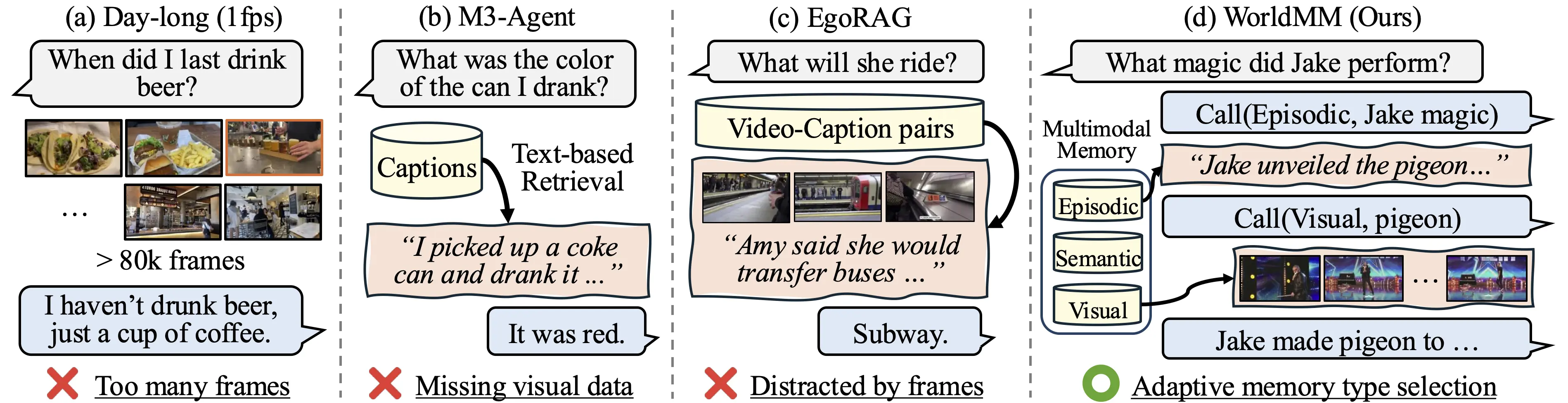
Recent advances in video large language models have demonstrated strong capabilities in understanding short clips. However, scaling them to hours- or days-long videos remains highly challenging due to limited context capacity and the loss of critical visual details during abstraction. Existing memory-augmented methods mitigate this by leveraging textual summaries of video segments, yet they heavily rely on text and fail to utilize visual evidence when reasoning over complex scenes. Moreover, retrieving from fixed temporal scales further limits their flexibility in capturing events that span variable durations.
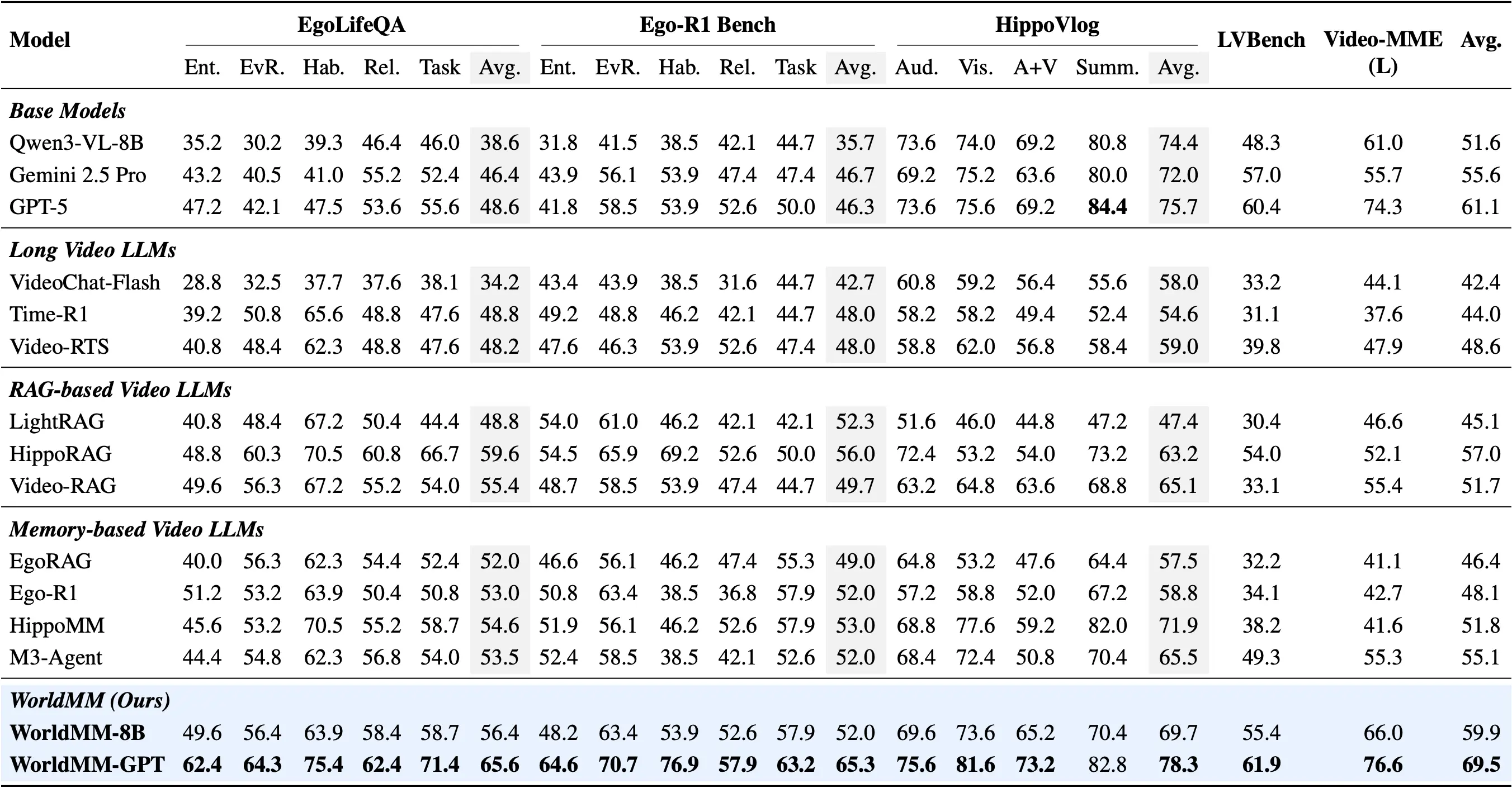
To address this, we introduce WorldMM, a novel multimodal memory agent that constructs and retrieves from multiple complementary memories, encompassing both textual and visual representations. WorldMM comprises three types of memory: episodic memory indexes factual events across multiple temporal scales, semantic memory continuously updates high-level conceptual knowledge, and visual memory preserves detailed information about scenes. During inference, an adaptive retrieval agent iteratively selects the most relevant memory source and leverages multiple temporal granularities based on the query, continuing until it determines that sufficient information has been gathered. WorldMM significantly outperforms existing baselines across five long video question-answering benchmarks, achieving an average 8.4% performance gain over previous state-of-the-art methods, showing its effectiveness on long video reasoning.